
Qu’est-ce que le SAP HANA Native Storage Extension (NSE) ?
SAP HANA Native Storage Extension (NSE) est une technologie de stockage qui intègre les supports suivants : Disque / Flash Drive / In-Memory. Cela permet d’optimiser l’utilisation de la mémoire In-Memory tout en conservant une gestion intégrée dans HANA. Comme décrit par la suite cela correspond à du stockage « Warm Data ». Les données qui sont accédées de manière moins fréquente, et principalement en lecture peuvent être stockées sans être chargées complètement en mémoire.
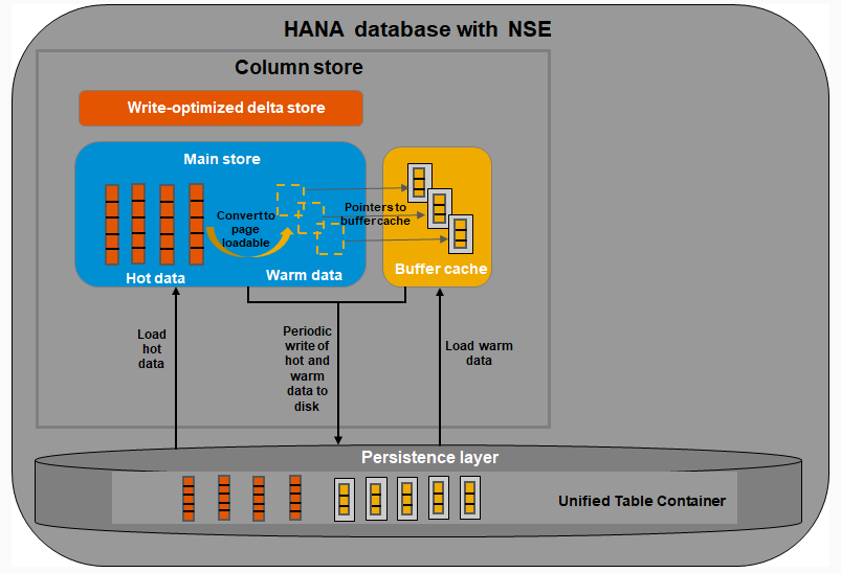
Figure 1 : NSE et Buffer Cache
Toutes données « Warm » stockées sur disque via le NSE ne nécessitent pas de mémoire « In-Memory » et ne sont donc pas soumises à Licence. Néanmoins pour être exploitées, ces données « Warm » remontent dans le « Buffer Cache » qui lui est une allocation d’espace « In-Memory » de l’ordre de 10% de la taille « In-Memory » de la base HANA. Comme nous allons le voir par la suite ces 10% ne sont pas exclusivement utilisés pour le « Buffer Cache » si les données « NSE » ne sont pas requêtées.
Quelques éléments trouvés dans le document ci-après attestent que la consommation de mémoire In-Memory dans le cadre des données NSE se limite à l’espace dédié dans le « Buffer Cache » : http://www.vldb.org/pvldb/vol12/p2047-sherkat.pdf
| 6. HANA Buffer Cache: With this purpose, we have introduced a buffer cache which is maintained separately from the resource manager to manage the page resources within a memory limit. |
| 6.2 Hot Buffer Retention and Page Stealing: Although the goal is to keep the memory footprint low by limiting usage through the limited buffer cache, the overall performance of the system should remain on par with that of the in-memory system. To achieve this, it is essential to reduce I/O by retaining frequently used buffers while maintaining enough free buffers for future usage |
| 6.4 Out-of-buffers and Emergency Pool: Queries fail if the buffer cache fails to find a free buffer despite a reasonable number of retries. In this case, the user is alerted to increase the buffer caches capacity. But some critical tasks like undo of a transaction, crash recovery, or continuous log replay on a secondary site, cannot fail as their failure would leave the database in an inconsistent state. |
Quelles sont les applications compatibles avec le « NSE » ?
Ce nouveau mode de gestion des données « Warm » est applicable dans les cas suivants :
1. HANA Natif (utilisation de la base sans motoriser une application)
- HANA 2.0 SP4 et après
2. HANA quand il motorise les applications suivantes :
- S/4HANA
- BW/4HANA
Quels sont les différents types de stockage sous HANA ?
- « Hot Data »
Ce type de donnée est utilisé pour : les activités opérationnelles critiques, le real time, et l’analytique. Les données sont toujours stockées en mémoire HANA pour avoir les meilleures performances. Le coût en termes de TCO est le plus élevé
- « Warm Data »
Cela concerne les données uniquement accédées en lecture de manière non fréquente. Il n’est pas nécessaire de stocker ces données de manière permanente dans la mémoire HANA, en revanche ces données sont accédées de manière intégrée et transparente avec les « Hot Data » via le « Buffer Cache ». Le TCO est optimisé par l’utilisation de disque.
- « Cold Data »
Uniquement pour les données en lecture, accès très peu fréquent, avec un stockage qui n’est pas intégré avec la base HANA mais accessible via les fonctionnalités de base fédérée de HANA.
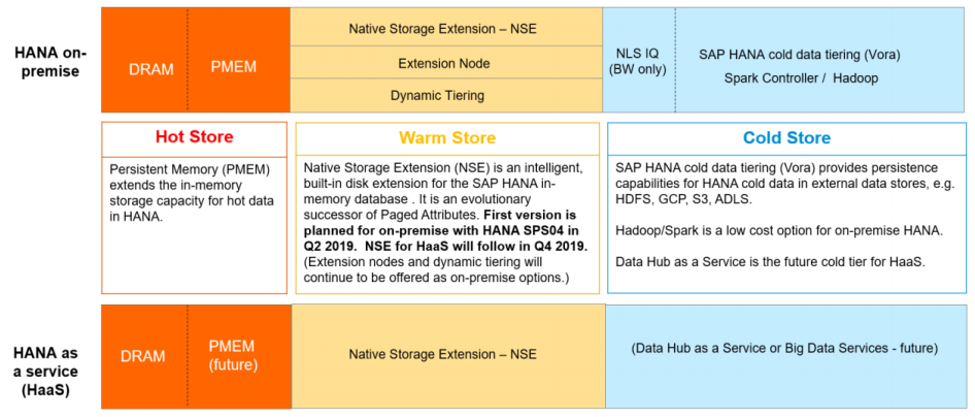
Figure2: SAP HANA Tiering
Quels sont les avantages en termes de TCO ?
Le stockage « In-Memory » coûte cher à cause des points suivants :
- Les licences : si vous opérez une base de Type « Full-Use » pour laquelle le coût de licence est directement lié à la taille de la Base In-Memory (uniquement). L’achat des licences est un coût CAPEX (une seule fois à l’achat) pour 64Gb (taille d’une unité HANA standard). Puis annuellement, la maintenance est due, entre 17 et 22% du coût d’acquisition.
- Les coûts d’infogérances : les serveurs doivent respecter un ratio entre le CPU et la quantité de mémoire « In-Memory » et sont configurés avec des spécifications très élevés, de fait l’augmentation de la mémoire du Server engendre une augmentation mécanique du coût mensuel du serveur.
Donc les mécanismes de stockage de données qui utilisent une technologie autre que In-Memory, même partiellement comme le NSE, apportent un gain de TCO pour les licences et le coût d’infogérance.
La mise en place du NSE a-t-il un impact sur mon architecture ?
Non. Et c’est un excellent avantage de cette technologie par rapport aux autres technologies tels que les « Extended Nodes ».
La croissance d’une base de données peut être opérée de deux manières :
- « Scale Out » : Ajout de serveurs supplémentaires qui fonctionneront en parallèle afin d’ajouter de l’espace de stockage est de distribuer la charge. Par le passé cette solution était recommandée et apportait des gains de performance, même si cela à un coût car une partie de l’espace « In-Memory » est utilisé pour faire fonctionner le cluster et donc l’allocation est moins efficace. De plus le coût Hardware est bien supérieur et il me semble que le « Scale Out » n’est plus recommandé par SAP en dessous d’une certaine limite de taille (4Tb ?)
- « Scale Up » : Ajout de mémoire et de CPU au serveur déjà en place.
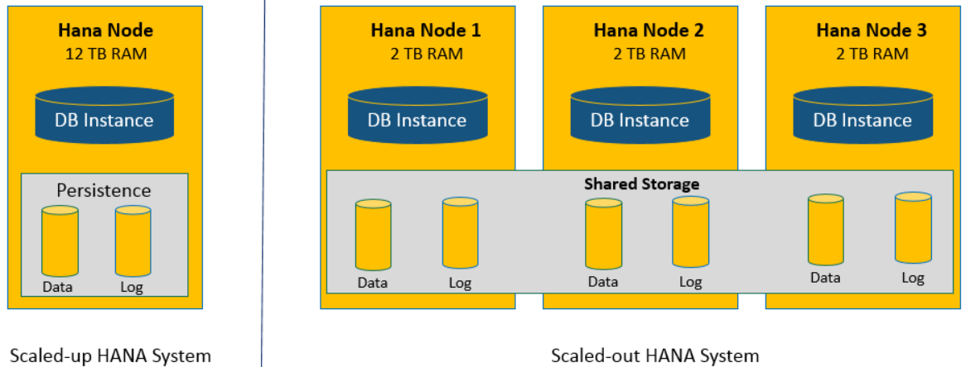
Scale Up | Scale Out
https://www.HANAtutorials.com/p/scale-up-or-scale-out-HANA-configuration.html
L’avantage du NSE est qu’il peut et doit se configurer en « Scale Up » donc sans avoir à ajouter plusieurs serveurs offrant une optimisation du TCO sans investissement dans des serveurs supplémentaires.
A contrario, la mise en place de « l’Extended Node » qui est une technologie plus ancienne, nécessite d’avoir déjà au moins deux nœuds. L’optimisation du TCO lorsque l’architecture ne comprend qu’un nœud HANA est donc beaucoup plus dégradée car il faut installer deux nœuds supplémentaires (1 Worker + 1 Extended Node).
Le NSE est-il envisageable lorsque HANA est configuré en « Scale Out » ?
Non. NSE n’est pas implémentable lorsque l’architecture est configurée en Scale-Out. Il faut considérer l’utilisation des « Extended Nodes » dans cette situation.
Le NSE a-t-il un impact sur les performances ?
Oui. Mais uniquement pour les données qui sont stockées sur le NSE. Cela est dû au fait que la base HANA n’accède aux données stockées sur disque du NSE que via le Buffer (de 10% de la base In-Memory), et qu’il est nécessaire en fonction de la taille des données qui sont requêtées de faire de multiples appels aux données du disque pour rafraîchir le buffer.
Il est possible d’optimiser la taille du buffer en se renseignant dans le document suivant : SAP HANA Administration Guide for SAP HANA Platform.
La mise en place du NSE, et le Buffer Cache réduisent-ils mon Allocation de « Hot Data » In-Memory ?
Non mais… Pour fonctionner le NSE nécessite un buffer qui permet de charger les pages stockées sur disque en mémoire « In-Memory ». Par défaut le buffer cache est activé, que le NSE soit implémenté ou non. Ce Buffer est dimensionné comme 10% de la taille de la mémoire « In-Memory ».
Cette mémoire est libre lorsque les données du NSE ne sont pas accédées et peut être utilisée pour d’autres « Hot Data », néanmoins lorsque les données NSE sont accédées, ce buffer lui est réservé et HANA va en priorité libérer de l’espace dans ce buffer pour son fonctionnement. (Illustration Figure 1).
Le NSE a-t-il une taille limite ?
Non. Selon la SAP Note 2771956, il n’y a techniquement aucune limite technique à la taille de la base NSE :
| The NSE data size per HANA system and tenant database is not limited by technical enforcement. Consider the following when storing large data sets in NSE on servers with limited memory capacity |
Néanmoins dans le blog (https://blogs.sap.com/2019/07/22/increase-HANA-data-capacity-with-sap-HANA-native-storage-extensionnse) on trouve des recommandations sur le ratio entre ce qui est stocké en NSE et le Buffer avec le ratio 1/8. En revanche, je ne retrouve pas cette information dans des notes SAP.
Si l’on conserve ces ordres de grandeurs, (qui peuvent évoluer), à savoir 10% pour le Buffer Cache et 1/8 pour le NSE on obtient à partir de 1TB de In-Memory les chffres suivants :
- In-Memory : 1000 GB
- Buffer Cache : 100 GB soit 10%
- SAP NSE : 800 GB soit 8x le buffer
Compte tenu des limites que peuvent poser la taille du Buffer Cache, est-il intéressant lorsque l’on souhaite stocker plus que 800 GB dans l’exemple ci-dessus d’utiliser le « Dynamique Tiering » plutôt que le NSE?
En autre termes, est-ce qu’un accès disque ne serait pas plus rapide que le mécanisme d’optimisation du NSE via la Buffer Cache lorsque l’utilisation est prévue comme largement supérieur à 8x le buffer ?
Un retour arrière est-il possible lorsque des tables sont stockées dans le NSE ?
Oui. Il est toujours possible de revenir en arrière lorsque les tables sont mises sur le NSE. Voir SAP Note 2799997
Pour approfondir le sujet
- 2799997 : FAQ: SAP HANA Native Storage Extension (NSE)
- 2771956 – SAP HANA Native Storage Extension Functional Restrictions
- 2785533 – Using SQL Commands to get recommendations from the NSE Advisor:https://launchpad.support.sap.com/#/notes/2785533
- NSE White Paper : https://www.sap.com/documents/2019/09/4475a0dd-637d-0010-87a3-c30de2ffd8ff.html
- NSE Guide on SAP help : https://help.sap.com/viewer/6b94445c94ae495c83a19646e7c3fd56/2.0.04/en-US/4efaa94f8057425c8c7021da6fc2ddf5.html
- SAP Blog : https://blogs.sap.com/2019/04/16/sap-HANA-native-storage-extension-a-native-warm-data-tiering-solution/
- SAP Blog : https://blogs.sap.com/2019/04/17/sap-HANA-native-storage-extension-a-cost-effective-simplified-architecture-for-enhanced-scalability/
- SAP Blog : https://blogs.sap.com/2019/07/22/increase-HANA-data-capacity-with-sap-HANA-native-storage-extensionnse./
- Theorical paper : http://www.vldb.org/pvldb/vol12/p2047-sherkat.pdf
Jérôme Blanc
Derniers articles parJérôme Blanc (voir tous)
- SAP HANA Native Storage Extension (NSE) | Q&A : Questions / Réponses - 6 février 2020
- Comment optimiser les investissements de votre Data Platform ? - 4 février 2020
- Ne dites plus « BI Manager » mais « Digital Data Manager » - 1 avril 2019