Si comme moi vous travaillez aussi dans le domaine de la « Business Intelligence » depuis plus de dix ans, si vous avez eu la chance d’accompagner des clients de toute taille, vous avez pu ressentir la vague de changements liée aux métiers de la donnée.
Derrière le terme de digitalisation parfois galvaudé, on a vu l’essor des plus grosses capitalisations mondiales en moins de 10 ans grâce à la valeur des données qu’elles possèdent ; démontrant l’importance stratégique de celles-ci. Par ailleurs, on entrevoit la robotisation des processus métier et informatique ou encore la découverte d’informations pertinentes via des intelligences artificielles.
Qu’est que cela veut dire pour vous en tant que BI Manager ?
Regardons en premier lieu ce qui est attendu des équipes et des systèmes informatiques. Nous évoquerons ensuite les nouveaux usages et les changements des paysages applicatifs qui ont été nécessaires pour permettre ces évolutions.
1 De nouvelles attentes
Avec l’avènement des plateformes BI SaaS (Power BI, Qlik Sense, SAP Analytics Cloud…), la construction d’états graphiques est plus que jamais à la portée des équipes métier. La construction de l’entrepôt de données ou des couches sémantiques restent, en revanche, des activités pour les experts informatiques.
Cependant, le temps et les budgets alloués à ces tâches essentielles se réduisent face aux attentes en gain d’efficacité.
1.1 Agilité
Il est difficile de justifier qu’il faille plusieurs jours de charge pour exposer des données brutes des systèmes sources, effectuer des jointures ou bien étendre le contenu de tables. Le métier attend une plus grande agilité car celle-ci permet l’innovation.
Voici ci-dessous une liste non exhaustive d’évolutions qui ont accru l’agilité et la capacité de délivrer rapidement :
- La modélisation en silo pour ne pas gérer les régressions => Applications Qlik Sense
- Les technologies permettant de répliquer les tables sans développement => SAP Hana
- Les mécanismes de virtualisation pour associer des sources sans les copier => Denodo
- Les performances In-Memory => Qlik Sense & SAP Hana
- Les liens « No-SQL » permettant des logiques sans modélisation => Mark-Logic
- La construction de rapports sur les systèmes transactionnels => Embedded Analytics
1.2 Temps réel
Un autre besoin est la nécessité d’effectuer des rapports sur des sources de données rafraîchies en temps réel ou presque. Ces questions se posent dans le cadre de la clôture annuelle sur des rapports opérationnels ou autres.
Les technologies Hana et le SLT (SAP Landscape Transformation Replication) permettent maintenant cette réplication en exposant des sources de l’ERP en quasi temps réel.
Alternativement, la création de rapports directement sur la couche ERP via les concepts d’« Embedded Analytics » devient la nouvelle cible en terme de reporting temps réel.
1.3 Mobilité
Les cas d’usage liés à la mobilité sont fréquemment présents que cela soit pour les systèmes de fabrication en usine « Manufactuing Exécution System » ou pour des managers qui souhaitent avoir leur états « Anytime, Anywhere ». Les solutions Cloud ou SaaS sont les meilleures solutions pour la mobilité. Néanmoins, les applications SAP, Qlik ou Microsoft ont toutes leurs applications mobiles.
1.4 Automatisation
L’automatisation de plus en plus de tâches bureautiques est attendue par le business car cela permet des nouveaux gains de compétitivité. Cela devient possible avec les concepts de RPA « Robot Process Automatisation », et plus généralement avec les bus et plateformes d’intégration de données que nous allons évoquer par la suite.
Prenons l’exemple de la finance, voici quelques exemples de tâches qui peuvent être automatisées :
- Extraire un compte de résultat et faire des vérifications élémentaires
- Charger ce compte de résultat dans un outil de consolidation
Toute tâche manuelle de bureautique, répétitive et déterministe, peut être automatisée via un processus RPA. Cette étape permet d’initier la création d’une interface qui est une solution plus robuste que le RPA.
1.5 L’Intelligence artificielle
L’intelligence artificielle est embarquée dans les nouveaux outils BI. Par exemple, SAP Analytics Cloud permet la recherche des critères ou axes d’analyses qui ont le plus d’influence sur l’analyse d’un indicateur. Ces fonctionnalités sont de plus en plus recherchées car elles permettent de mettre un pied dans la data science. Ces nouvelles attentes s’expriment à travers de nouveaux usages que nous parcourrons dans le chapitre suivant.
2 De nouveaux usages
Dix ans plus tôt l’innovation passait par la mise en place de Dashboard : l’évolution synthétique et graphique des états d’analyse détaillés. Plus récemment avec la multiplication des sources, les usages sont devenus plus poussés et plus scientifiques
2.1 La genèse : « Corporate reporting »
Le premier besoin d’une société, cotée ou non, est d’avoir des états qui lui permettent de piloter son activité en évaluant l’activité passée :
- Produire un compte de résultat ou un bilan sur l’année passée ?
- Volume d’achats ?
- Niveau de stock ?
- …
Toutes ces questions et les états qui permettent d’y répondre sont à classifier dans la catégorie de « Corporate Reporting ». C’est le point de départ sur l’échelle de maturité BI.
2.2 Multiplication des usages
Plus récemment le développement des technologies « In-Memory » et Web ont permis de démocratiser des outils d’exploration et de data visualisation.
Data Visualisation
Ci-dessous un exemple d’outil de visualisation avec SAP Analytics Cloud qui permet une exploration des données de manière intuitive.
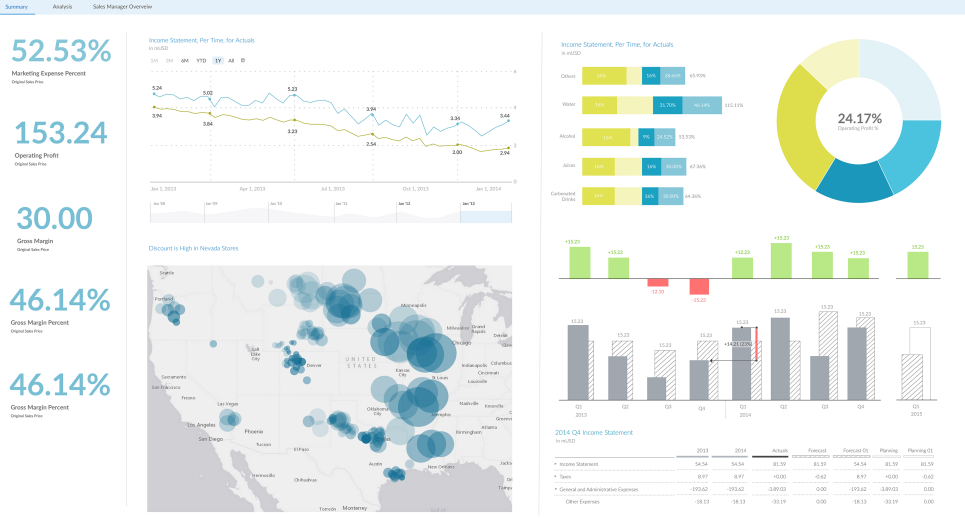
Les outils de DataViz (Data Visualisation) permettent à l’utilisateur d’explorer graphiquement un DataSet tout en interagissant avec le rapport. Cela est rendu possible sur des centaines de millions de lignes grâces aux technologies « In-Memory ».
Dans les outils de DataViz on retrouve de multiples sous-catégories :
- Rapport Figé
- Analyse Libre
- Dashboard
- …
Simulation
La simulation est un exercice bien différent, souvent appelé « what-if Analysis ». Les questions adressées par ces usages peuvent être :
Comment gérer la production si l’on remporte un nouveau contrat ?
Quel sera l’impact sur le profit si le coût des matières premières varie ?
Pour résumer, ces outils permettent de simuler l’impact de décisions ou la variation de paramètres extérieurs.
Anaplan est un expert du marché, dont voici ci-dessous une visualisation :
Data Science
La Data Science regroupe les usages liés à l’analyse des données par des procédés mathématiques ou statistiques. Ces analyses statistiques permettent, entre autre, de prévoir le futur en se basant sur l’apprentissage de schémas passés. Cette branche de la Data Science s’appelle l’analyse prédictive.
La Data Science est souvent liée au Machine Learning et au Data Mining. Ces méthodes scientifiques regroupent les procédés suivants :
- Supervised learning (classification • regression)
- Clustering
- Dimensionality reduction
- Structured prediction
- Anomaly detection
- Artificial neural networks
- Reinforcement learning
Pour répondre aux nouvelles attentes et aux nouveaux usages, le paysage applicatif s’est enrichi au fil du temps.
3 L’évolution des paysages applicatifs
3.1 Quand le Datawarehouse était la couche supérieure du système d’information
Historiquement les diagrammes et la représentation des flux de données étaient toujours alignés avec le model suivant : Data Source => ETL => Data Warehouse => Reporting layer.
L’idée principale était la rationalisation de toutes les données dans le même et unique Data-Warehouse pour des notions d’efficacité et d’unicité du stockage des données.
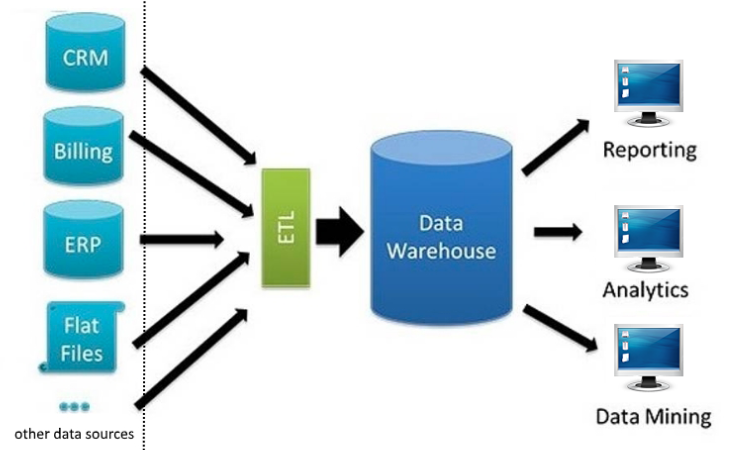
Cependant, ces concepts se sont montrés trop restrictifs et la diversification des usages a nécessité une représentation plus flexible.
3.2 La donnée devient le cœur du paysage applicatif
Les nouveaux schémas d’intégration et de consommation de données ont 3 points fondamentalement différents par rapport à la vision antérieure : le bus de données ou plateforme d’intégration, les multiples entrepôts de données et la virtualisation.
Le schéma partagé ci-dessous est une vue de la « Modern Data Platform » par SAP :
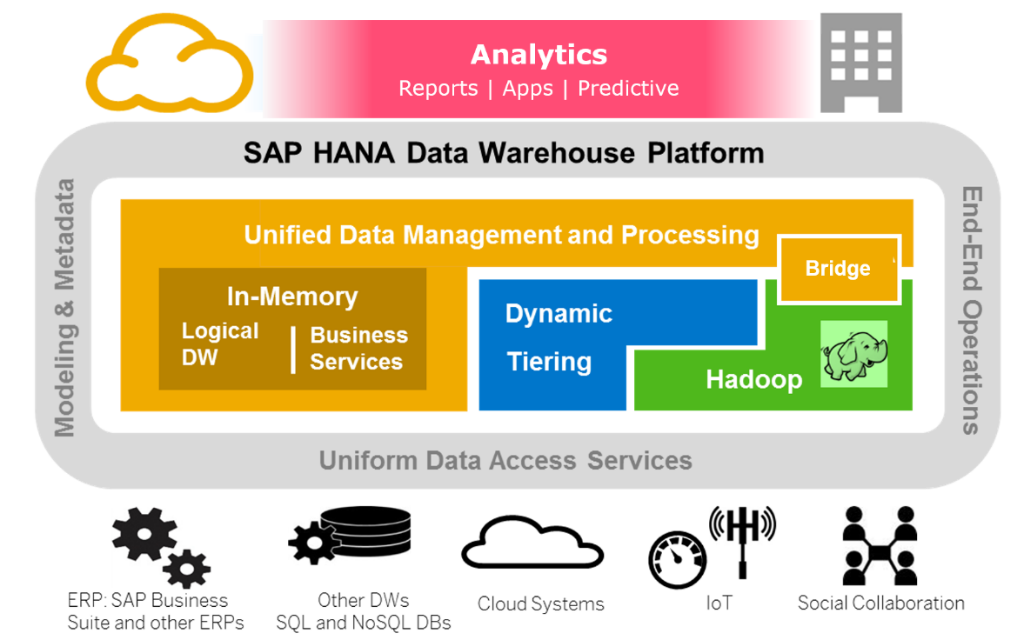
La mise en place d’un « Bus de Données » ou d’une « Plateforme d’Intégration »
Un « Bus de Données », une « Plateforme d’Intégration » ou « Data Intégration Backbone » s’illustre sur le schéma ci-dessus par la notion de « Uniform Data Access Service ».
Le concept tient en la mise en place d’un middleware connectant tous les points qu’ils soient source ou destination. La plateforme d’intégration est orientée service et doit être flexible. Lorsque la plateforme est configurée, l’utilisation de webservices permet de contrôler la propagation des données.
L’utilité de la plateforme d’intégration est renforcée par la multiplication et diversification des sources de données mais aussi par la multiplication des plateformes de stockage : In-memory, IOT, No-SQL.
En comparant les architectures avant/après, on voit l’apparition de données non structurées telles que l’IOT et les outils de collaboration, ainsi que les données hébergées dans le cloud.
Les outils « Dell Boomi » et « Kafla » sont des exemples de plateforme d’intégration d’un côté et de streaming de données de l’autre.
Multiples Entrepôts de données
Les plateformes de stockage de données se sont spécialisées sur des usages spécifiques : la gestion des données de base, la gestion des données agrégées, la réplication des données source en temps réel et la gestion des données non structurées.
Pour adresser les besoins listés ci-dessus de multiples outils et éditeurs sont nécessaires. Voici quelques exemples de ces outils :
- SAP BW : données agrégées
- SAP Hana : réplication de données en temps réel
- Mark-Logic : bases No-SQL
- Hadoop : données issues des IOT
- …
En comparant les architectures avant/après, on observe le passage d’une à plusieurs plateformes de stockage.
Virtualisation
La multiplication des plateformes de stockage et des outils de reporting pose les questions suivantes :
Comment peut-on créer des états sur de multiples sources de données ?
Comment implémenter des vues avec une couche sémantique utilisable par plusieurs outils de visualisation ?
La réponse à ces deux questions est la couche de virtualisation de données.
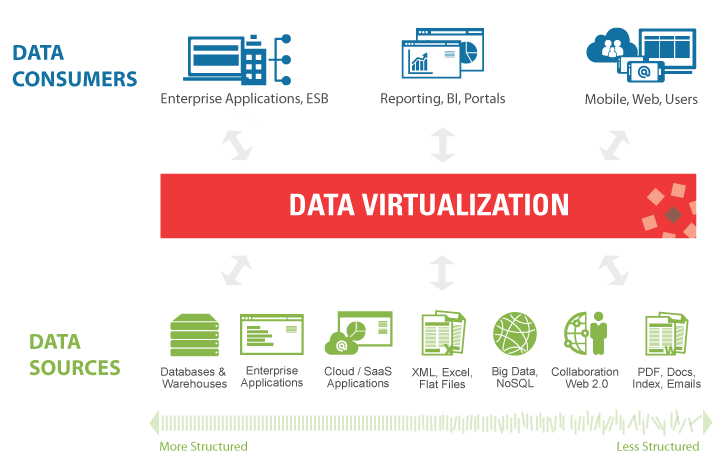
L’illustration ci-dessus vient de l’éditeur de logiciel spécialisé en virtualisation « Denodo ».
La couche de virtualisation permet de :
- Créer une couche d’abstraction logique avec la source de données
- Créer une couche sémantique couvrant les données structurées et non structurées
- Provisionner de manière agile des nouvelles sources de données
- Fournir une gouvernance des données unifiées.
SAP Hana fournit aussi les fonctionnalités de virtualisation permettant de provisionner des vues sur des applications cloud comme Concur ou SuccessFactor, ou des bases IOT comme Hadoop.
3.3 Le rôle de « l’Urbaniste des systèmes d’information »
Comme nous l’avons vu ensemble la multiplication des outils et des usages, l’intégration accrue avec les bus de données et les solutions de virtualisations nécessitent une vraie stratégie d’entreprise. Le rôle de chaque application dans le paysage applicatif doit être défini via un plan d’occupation des sols POS. Cette mission est portée par l’urbaniste des systèmes d’information.
4 Conclusion :
Pour conclure, nous pouvons réfléchir à l’utilisation des outils liés aux données et s’assurer qu’ils soient utilisés de la manière la plus pertinente dans le paysage applicatif.
Accompagner les nouvelles attentes via des nouveaux outils nécessite de remettre en question fréquemment le périmètre d’opération de ces outils.
Par ailleurs comme le dit un célèbre dicton, « le mieux est l’ennemi du bien », la complétude de la vision est une chose mais la capacité d’implémenter en est une autre. La multiplication des technologies peut avoir comme effet néfaste de rendre toute exécution compliquée.