
Hana Stored Procedure
Qu’est-ce qu’une procédure stockée Hana (Hana Stored procedure)? Quand faut-il les utiliser et quelles sont ses différences face à d’autres objets qui s’y apparentent ? Nous répondrons à ces questions dans la suite de cet article.
Qu’est-ce qu’une procédure stockée ?
Une procédure est une suite de commandes SQL regroupées dans un seul bloc. Ce code est précompilé et peut-être exécuté sur demande, soit manuellement par une commande SQL (CALL, EXECUTE) soit par une planification (Job) ou en l’appelant dans une autre procédure. La procédure stockée ne permet pas seulement de lire la donnée mais permet également de la modifier grâce aux fonctions de manipulation (INSERT, DELETE, UPDATE). Une fois mise en place elle peut donc être réutilisée dans vos différents flux de données.
Création d’une Procédure
Il y a deux manières de créer une procédure :
- Soit en la créant directement dans le répertoire (« repository »)
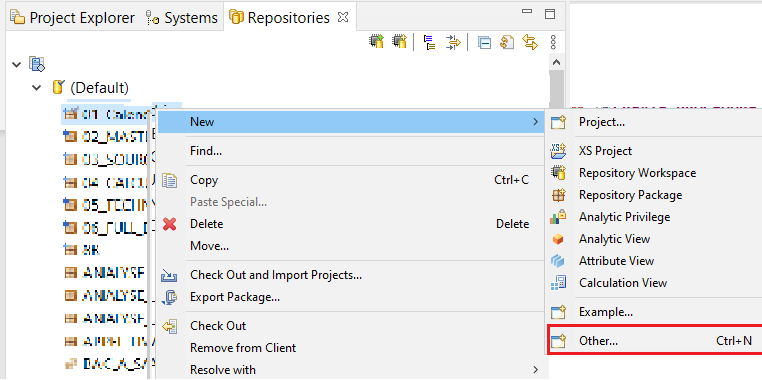
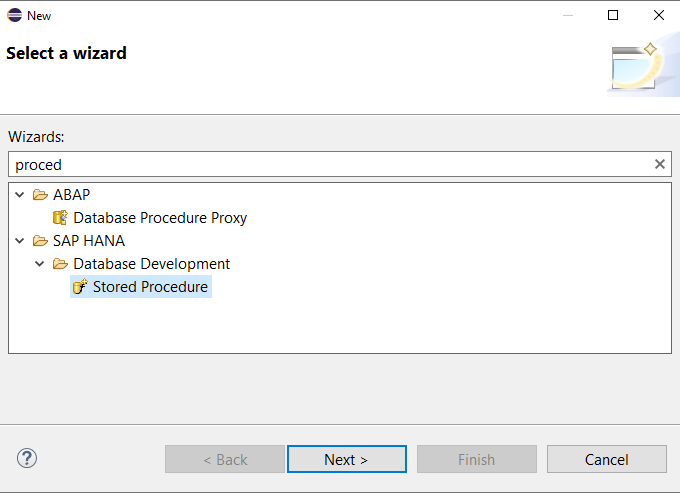
- Soit en la créant gâce à une commande SQL telle que :
CREATE Nomdelaprocédure AS [Code SQL]
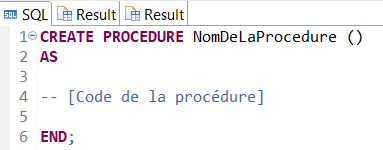
La première option est plus recommandée car une fois l’objet HDB créé il plus facilement transportable et réutilisable.
Stored Procedure vs Table Functions
La procédure stockée peut s’apparenter à la « Table Function » est une fonction qui retourne une table qu’on peut requêter de la même manière qu’une table de base de données avec un: FROM [Nom de la fonction]. Les deux objets peuvent dans certains cas être utilisés de la même manière, mais voici les points sur lesquels ils diffèrent :
| Procédure stockée | Table Function |
|---|---|
| Ne retourne pas forcément une valeur | Retourne forcément une table |
| Lecture + écriture (INSERT UPDATE SELECT) | Opération de lecture seulement (SELECT) |
| Ne peut pas être utilisé dans une vue calculée | Peut être utilisé dans une vue calculée |
| Compilé une seul fois | Compilé à chaque appel |
| Peut faire partie intégrante du flux de données | Utilisé surtout pour du reporting |
Il est possible de partir d’une table existante comme source d’une procédure stockée. On lui applique un certain nombre de transformations (filtres, DML, jointures…) pour sortir avec une nouvelle table qui sera exploitable dans des vues calculées. Il suffit ensuite de créer un job qui se chargera de faire tourner la procédure pour avoir une table qui se rafraichit à intervalle de temps régulier. La table function aussi permet de faire certaines modification simple tel que la jointure, elle ne permettra pas en revanche d’utiliser le opérations de DML.
La procédure retourne une table de la même manière qu’une « table function » mais les transformations sont possible grâce à la procédure.
Exemple de code d’une procédure simple :
Cet exemple illustre ce qui est possible de faire entre autres dans une procédure, le SELECT, la jointure et les commandes de manipulation de données (INSERT, TRUNCATE, UPDATE).
Il est aussi possible de définir des « Paramètre d’entrée » qui fonctionnent de la même manière que ceux des vues Hana classiques. Le paramètre d’entrée va permettre d’optimiser les performances de la procédure en réduisant le nombre de données à traiter par exemple.
La procédure ci-dessous contient donc un paramètre d’entrée qui s’appelle FIELD1_IP et vient filtrer le champ FIELD1.
BEGIN
temp = SELECT
T1. »FIELD1″,
T1. »FIELD2″,
T2. »FIELD3″
FROM « TEST1 » T1 LEFT JOIN « TEST2″ T2
ON T1. »FIELD1″ = T2. »FIELD1″ AND T1. »FIELD2″ = T2. »FIELD2″
WHERE T1. »FIELD1 » = :FIELD1_IP;
TRUNCATE TABLE « TABLE »;
INSERT INTO « TABLE » ( T3. »FIELD1″,
T3. »FIELD2″,
T3. »FIELD3″
FROM :temp T3;
END;
Conclusion
Quand il s’agit de développer une logique à mettre en place dans un flux de données, la procédure stockée offre beaucoup d’avantages : les fonctions DML, la réutilisabilité, des performances optimisées… La procédure comme la table function sera potentiellement un passage obligé dans la réalisation de votre flux de données, car l’une comme l’autre vous permettent de faire des transformations pas réalisable en utilisant des vue calculées Hana classiques.
N’hésitez pas à consulter les autres Blogs écrits par nos consultants pour rester informé à propos des dernières technologies SAP ainsi que des différents projets menés par nos équipes.