
Qu’est-ce que le stockage en colonne ?
Lors du stockage d’une table de base de données, les valeurs qu’on se représente aisément comme une feuille de calcul, doivent être transformées en bits de données et stockées en chaines. La question est alors de choisir comment seront organisées ces chaines, et deux options principales s’offrent à nous : le stockage en lignes ou en colonnes.
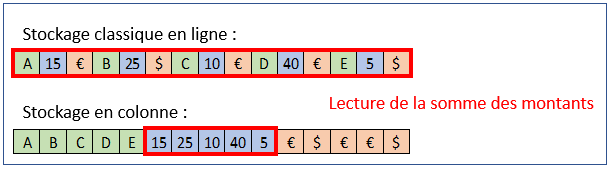
Si le stockage en ligne consiste à enregistrer sur le disque les lignes d’une table les unes après les autres, avec un index par ligne, le stockage en colonne met lui les colonnes bout à bout de la même façon, ce qui pourrait être représenté comme cela :

Quel intérêt ?
Le premier avantage est d’améliorer les performances de lecture d’un sous ensemble de tables. Ainsi un select de la somme des montants dans une table stockée en ligne va devoir lire l’ensemble des lignes afin d’en remonter le montant. En colonne, il suffira de lire la colonne ‘montant’ en y accédant par son index et d’ignorer les autres.
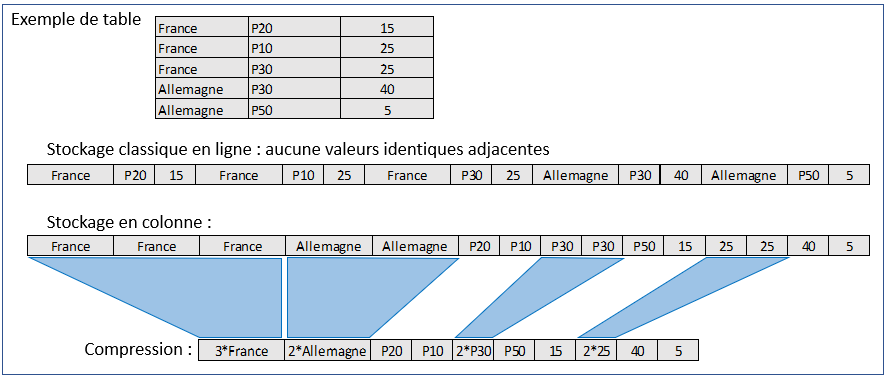
Second avantage, et non des moindres dans une logique de stockage complet « in memory », le taux de compression est bien meilleur avec le stockage en colonne car les valeurs identiques se suivent plus souvent dans les tables triées.
L’inconvénient ?
Afin d’optimiser les lectures et le volume de stockage, les tables en colonne sont donc triées, indexées et compressées. Le revers de la médaille est qu’il est bien plus long d’y insérer de nouvelles lignes, au lieu de simplement ajouter une ligne complète à un index donné de la table. Il est nécessaire de parcourir chacune des colonnes pour y insérer une valeur.
La solution apportée par SAP HANA
Afin de contourner ce problème de performances d’insertion, SAP HANA utilise le « Delta merge ». Cela consiste à gérer pour chaque table une version principale, indexée et compressée, ainsi qu’une version temporaire sans index ni compression où il est très rapide d’insérer de nouveaux enregistrements. De façon transparente, chaque lecture de table pointe sur ces deux versions ; ainsi le résultat d’un insert est toujours accessible en temps réel.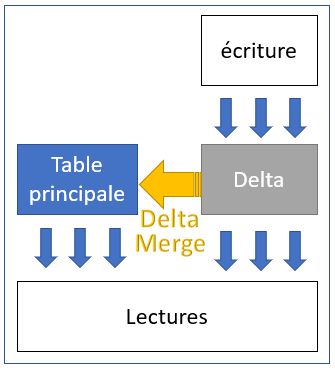
Evidemment les performances de lecture se dégradent progressivement avec l’augmentation de taille de la table temporaire. Le moteur HANA se charge alors régulièrement (selon ses ressources disponibles) de réaliser le « Delta merge » sur ces tables pour les fusionner et ainsi créer une nouvelle version principale, complète et optimisée.
A noter que si le Delta merge est lancé automatiquement par le moteur de SAP HANA, en fonction de son paramétrage (pour un système S4/HANA par exemple), il est désactivé par défaut dans les systèmes BW4/HANA. En effet, il serait contre performant de lancer un Delta merge pendant le chargement d’un DTP alors que celui-ci n’est pas terminé.
L’option de lancer le Delta merge en fin d’exécution de DTP est par défaut cochée à la création d’un nouveau DTP, et un processus pour le lancer est disponible dans les process chains.
En deux mots
Le stockage en colonne existe depuis longtemps mais il était utilisé que pour des besoins précis de base données avec très peu d’écritures. C’est grâce aux avancées techniques en termes de mémoire et de processeur que SAP a pu contourner ses limitations et l’utiliser à son plein potentiel dans HANA. Aujourd’hui 99% des tables HANA sont en stockage colonne.