
What is column storage?
When storing a database table, the values, which are easily represented as a spreadsheet, must be transformed into data bits and stored as strings. The question is then to choose how to organise these strings, and there are two main options: storage in rows or columns.
If row storage consists of storing the rows of a table on the disk one after the other, with an index per row, column storage puts the columns end to end in the same way, which could be represented like this:

What is the point?
The first advantage is to improve the reading performance of a subset of tables. Thus a select of the sum of the amounts in a table stored in row will have to read all the rows in order to find the amount. In columns, it will suffice to read the 'amount' column by accessing it via its index and ignore the others.
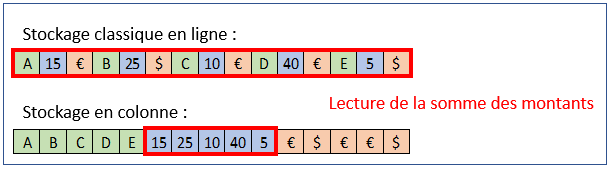
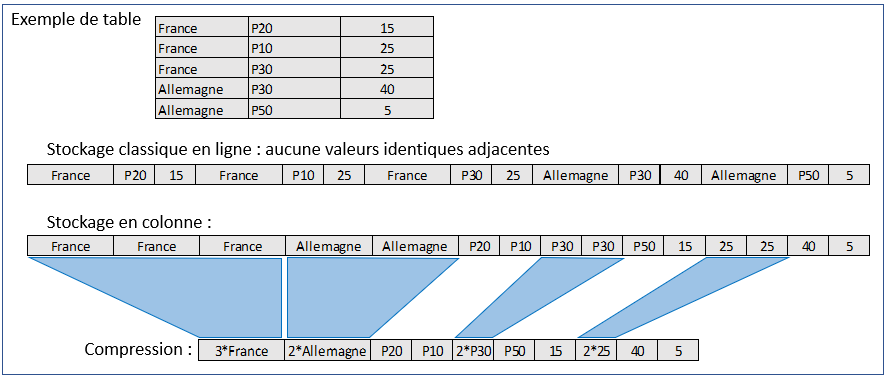
Secondly, and not least in a logic of complete "in memory" storage, the compression rate is much better with column storage because identical values follow each other more often in the sorted tables.
The disadvantage?
In order to optimise reads and storage volume, columnar tables are therefore sorted, indexed and compressed. The downside of this is that it takes much longer to insert new rows, rather than simply adding a complete row to a given index in the table. It is necessary to go through each column to insert a value.
The SAP HANA solution
In order to get around this problem of insertion performance, SAP HANA uses the "Delta merge". This consists of managing for each table a main version, indexed and compressed, as well as a temporary version without index or compression where it is very quick to insert new records. In a transparent way, each table read points to these two versions; thus the result of an insert is always accessible in real time.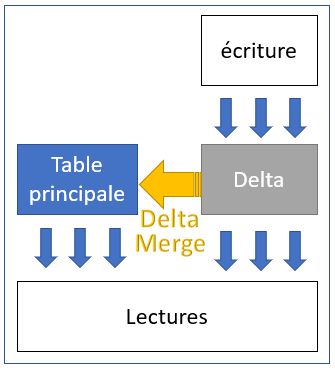
Obviously the reading performance gradually degrades with the increase in size of the temporary table. The HANA engine then regularly (depending on its available resources) performs the "Delta merge" on these tables to merge them and thus create a new, complete and optimised main version.
Note that while the Delta merge is launched automatically by the SAP HANA engine, depending on its settings (for an S4/HANA system for example), it is deactivated by default in BW4/HANA systems. Indeed, it would be counterproductive to launch a Delta merge during the loading of a DTP when it is not finished.
The option to run the Delta merge at the end of a DTP run is checked by default when a new DTP is created, and a process to run it is available in the process chains.
In a nutshell
Columnar storage has been around for a long time, but it was only used for specific database needs with very few writes. It is thanks to technical advances in terms of memory and processors that SAP has been able to bypass its limitations and use it to its full potential in HANA. Today 99% of HANA tables are in columnar storage.